The Segwit2x hard fork was called off a little over a week ago in an email post to the 2x mailing list. Several parties threatened to split the network anyway, and we eagerly waited for block 494784 to see whether someone would mine the 2x hard fork or not.
As it turns out, there was a bug in the Segwit2x software which caused the client to stop at block 494782. In this article, I’m going to examine the details of what caused the software to stop, why it stopped a block before it was supposed to and what would have happened had Belshe, et al, not cancelled the hard fork a week early.
The Setup
The 2x part of the hard fork had been planned for the past 6 months. The New York Agreement was agreed to in late May, the code was written mostly in June and the btc1/Segwit2x software was released in July.
The specifics of the NYA required that:
- Segwit be activated at 80% instead of 95%
- 2x hard fork be activated within 6 months (of May 23)
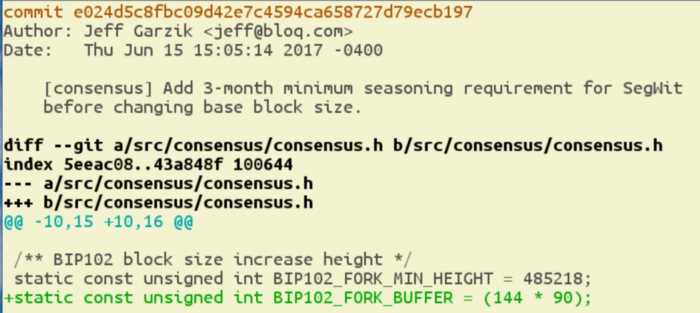
The software was created in the btc1 repository, with lead developer, Jeff Garzik. To make the first condition happen, they incorporated James Hilliard’s BIP91 proposal, which indeed successfully activated Segwit on the network on August 24 at block 481824.
To make the second condition happen, btc1 software included a clause that activated a hard fork to double the block size exactly 144*90 blocks after Segwit activation. This number was chosen because 10 minutes per block means about 144 blocks per day, so 144*90 blocks would take about 90 days. This put the forking block height at 494784 and the actual fork around November 15 or so, which would indeed satisfy the second part of the NYA.
The Bug
There were a limited number of differences in the btc1 codebase, compared to Bitcoin Core. In total, there were about 500 lines of changes, most of which weren’t consensus-critical. Yet, there were at least two bugs in the 100 or so changed lines to support a hard fork at block 494784.
To understand this bug, it might be easiest to take a look at the set of changes that first introduced the idea of forking after 144*90 more blocks:


You can see that there’s a parameter for how long it would take after Segwit activation to double the block size. Specifically 144 * 90 blocks. In the code this is a concept called “Segwit seasoning”. Basically, this lets Segwit exist by itself without a doubling of block size for 144*90 blocks.
To figure out whether it’s time to allow larger blocks, the boolean variable fSegwitSeasoned is set to True if 144*90 blocks have passed, False if not. The next if statement specifically utilizes this boolean to figure out what the maximum base block size (block size minus witness data) is supposed to be (2mb if True, 1mb if False). Normally, base blocks would be rejected if the block is greater than 1mb, but here, we see that blocks are rejected if the block is greater than 2mb should fSegwitSeasoned is True. This is the critical part of the consensus code that rejects too-large blocks and thus requires a hard fork.
To actually figure out whether fSegwitSeasoned should be set to True or False, the code here uses the VersionBitsState function. Specifically, the code is supposed to look at the block 144*90 blocks previous and check if Segwit was active on the network. If Segwit was active 144*90 blocks ago, that means >1MB base blocks are legal for this block. That’s what this is supposed to test.
VersionBitsState
There’s a subtle bug here and it has to do with how VersionBitsState is called. To understand, take a look at the actual function defined in versionbits.cpp:

This is going to look like gobbledygook unless you know something about the codebase, but allow me to explain. The first argument of the VersionBitsState function is supposed to be a pointer to a block. The variable name pindexPrev indicates it’s not the pointer to the block itself, but the block’s parent. In fact, every other call to VersionBitsState in the validation.cpp file specifically uses the pointer to the parent block, not the block itself for that reason.
Here’s the problem: pindexForkBuffer above is 144*90 blocks before the current block, not the current block’s parent. So in essence, we are looking at whether the block 144*90–1 before the current one has Segwit activated or not. We are off by 1 block and thus, larger blocks get activated 1 block earlier.
How did this not get caught?
This particular set of changes was part of a much larger pull request found here. The pull request has 221 comments, most of which are arguing over the definition of 2MB blocks. You can see that this particular commit doesn’t actually make it into this pull request until way lower on the page. Only one person seems to have approved the changes (opetruzel) and there are complaints near the end by deadalnix (he of Bitcoin Cash fame) about this pull request not having enough tests.
Errors on Errors
This code snippet of calculating 144*90 blocks past was accepted as the right way of doing things and nobody caught the fact that this would cause problems later.
In order to make sure that the 2x hard fork wouldn’t be overtaken by the 1x chain and reorganized (basically, completely wiped out), they instituted a rule for wipeout protection. This requires the forking block to have greater than 1MB base block size. The same logic as above was used and essentially forced block 494783 to have a base block size >1MB, not block 494784.
This is why btc1 is stuck on 494782, because btc1 software is waiting for a greater than 1MB base block at 494783.
But Wait, There’s More
As if this off-by-one bug wasn’t enough, there’s another bug in the BlockAssembler code. BlockAssembler is part of miner.cpp, which is the code responsible for creating new blocks. Generally, this is only code useful to miners as they’re the only ones that actually create new blocks.
Specifically, the variable fWitnessSeasoned is not initialized, but gets used. This is undefined behavior as Pieter Wuille has shown.


Why is this important? Well, it turns out that this particular variable determines the maximum block size and weight that the software will make! If this variable is false, then the software will never make a large enough block to fork the chain since the maximum block weight will be 4,000,000 and not 8,000,000 as the specifications of the 2x hard fork require. Conversely, if this variable is true, then the software will generate invalid blocks before the fork of the chain. So it was possible that even if a miner wanted to mine on 2x, this software wouldn’t let them!
This code change was introduced in this pull request and once again Jeff Garzik was the author and it was merged with perhaps one reviewer (FaysalM) who didn’t catch the bug.
What would have happened if 2x wasn’t cancelled?
Miners that were planning to fork with 2x would naturally have thought 494784 was the block since Jeff Garzik and the segwit2x team have stated numerous times that this was the forking block.
Even if miners weren’t using the code above which would possibly have prevented them creating bigger blocks, they would have customized their software to find larger blocks for block 494784, not 494783. This would have caused the same stall at block 494782 and everyone would have started to try to debug what was causing the problem.
Most likely, some miner would have figured things out and simply mined a large block to fork 2x anyway. How long that would have taken is anyone’s guess, but it’s pretty clear this would have been a PR disaster.
More than that, as Greg Maxwell points out here, exchanges would have frozen accounts as of block 494784, not 494783, so all the balances for 2x coins would have been off depending on who got in on block 494783. This again would have caused some serious damage.
Conclusion
Reviewing and testing consensus changes is really, really hard. It looks like btc1 had exactly 1 coder and 1 reviewer for these critical consensus changes and that simply isn’t enough to detect subtle bugs like the first or obvious bugs like the second. What’s more, because the off-by-one change was accepted at a fairly early date (~June 15), later on when the code was used for wipeout protection, the code was assumed to be good due to a previous “review”.
Essentially, even one or two weak reviews in a chain of reviews can break the entire consensus system with a catastrophic bug.
Hopefully, this can be an object lesson in making sure critical changes are reviewed very thoroughly. Stay safe and go thank the developers that do the hard work of not just coding, but reviewing.
Are you a developer that wants to get into Bitcoin and blockchain? Sign up for Programming Blockchain Seminar in Austin, Charlotte, London, Amsterdam or Seoul!
Want to get curated Technical Bitcoin News? Sign up for the Bitcoin Tech Talk newsletter!
Comments are closed